OLTP (On-Line Transaction Processing)
주 컴퓨터와 통신 회선으로 접속되어 있는 복수의 사용자 단말에서 발생한 트랜잭션을 주 컴퓨터에서 처리하여 그 결과를 즉석에서 사용자 단말 측으로 되돌려 보내 주는 처리 형태. 트랜잭션이란, 단말에서 주 컴퓨터로 보내는 처리 단위 1회의 메시지로, 보통 여러 개의 데이터베이스 조작을 포함하는 하나의 논리 단위이다. 예를 들어, 데이터베이스 내의 어떤 표의 수치를 변경하는 경우, 그 표와 관련된 다른 표의 수치도 변경하지 않으면 데이터 무결성(data integrity)을 유지할 수 없다. 이런 경우에는 2개의 처리를 1개의 논리 단위로 연속해서 행해야 하는데, 이 논리 단위가 트랜잭션이다. 1개의 트랜잭션은 그 전체가 완전히 행해지든지, 아니면 전혀 행해지지 않든지 둘 중 하나여야 한다. 그 이유는 1개의 트랜잭션 처리 도중에 그 트랜잭션의 처리를 중지하면 데이터 무결성이 사라질 우려가 있기 때문이다. 이러한 온라인 트랜잭션 처리(OLTP)의 특성에 적합하게 개발된 컴퓨터가 내고장형 또는 무정지형 컴퓨터(FTC)이다. 그리고 이전에는 범용기 중심이던 OLTP 시스템을 유닉스에도 구축하게 되었는데, 유닉스용의 트랜잭션 처리(TP) 모니터가 여러 가지 개발되어 있어서 성능과 가용성을 높이고 있다. 최근에는 업계 표준인 분산 컴퓨팅 환경(DCE)에 대응하는 TP 모니터 제품이 많이 출현하여 유닉스 기계에 기간 업무의 OLTP 시스템을 구축하는 경향이 늘고 있다.
구분 OLTP OLAP 데이터의 구조 복잡 (운영 시스템 계산에 적합) 단순(사업 분석에 적합) 데이터의 갱신 순간적/동적 주기적/정적 응답 시간 2, 3 초 ~ 몇 초 이내 수 초 ~ 몇 분까지도 가능 데이터의 범위 과거 30 일 ~ 90 일 과거 5 년 ~ 10 년 데이터 성격 정규/핵심 업무 데이터, 비정규/read-only 데이터,index 에 의존 데이터의 크기 수 Giga Byte 수 Tera Byte 데이터의 내용 현재 데이터 기록 보관된, 요약/계산 데이터 데이터 특성 거래처리(transaction) 중심 주제(subject) 중심 데이터 액세스 빈도 높음 보통 혹은 낮음 데이터의 사용법 고도로 구조화된 연속 처리 고도로 비구조화 된 분석 처리 쿼리의 성격 예언 가능, 주기적 예측하기 어렵고, 특수하다
OLTP와 OLAP의 비교
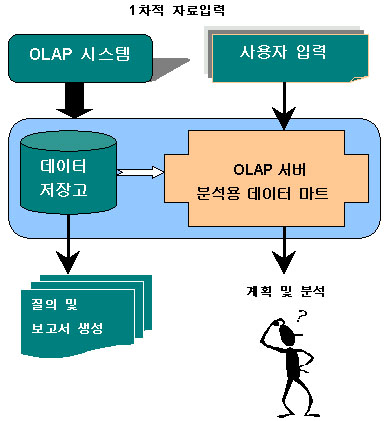
OLTP은 매일매일의 기업운영을 가능하게 하는 거래처리 시스템이고, OLAP은 다차원 분석에 의해서 기업이 나가야 할 방향을 설정할 수 있는 것이다. OLAP의 목적은 최종사용자가 기업의 전반적인 상황을 이해할 수 있게 하고 의사결정을 지원하는데 있다. OLTP와 OLAP의 비교항목을 요약하면 다음과 같다.
mission critical 데이터
 7
7




